
What you will learn in this post
In my last tutorial we saw how to use Java 8 with Spark, Lombok and Jackson to create a lightweight REST service. One thing we did not examine was how to persist (store) data. In this post I would like to describe a way to organize the integration of the database layer with the rest of your Spark application.
In this post we will see
- how to understand if an ORM is the right choice for you
- how Sql2o (a framework to interface with a database) works
- how to integrate Sql2o with Spark
What we will not see in this post (but probably in a future one):
- how to test the controllers
- how to test the SQL code
Most of what we will learn could be adapted to other systems like myBatis or also ORMs like Hibernate. In my opinion the important thing is to come up with a design that is easily testable. Ideally you should write both unit tests and functional tests, and create a reliable REST service based on Spark.
To ORM or not to ORM?
The first question is: “What kind of database library should we use?” There are different approaches out there, with their pros and cons. We basically can divide them in two families:
- the Object-Relational mappers (ORM) approach (e.g., Hibernate)
- the pure SQL approach (e.g., myBatis, Sql2o)
The basic idea is that ORMs abstract the database and provide classes representing our tables. They tend to be database independent and that means you could use the same code to integrate with a MySQL or a PostgreSQL database. They also generate the SQL code for you. In the pure SQL approach instead basically we write the SQL code and wrap each query in a function.
While the idea of abstracting details is always tempting, the problem is that mapping a relational database into an object oriented schema only works up to a certain point. The abstraction tends to be leaky because you end up needing to do things that makes perfect sense into a relational schema, but do not fit into the object-oriented abstraction. While SQL insert statements map well to object instantiation, a delete maps to an object destruction, and an update maps to invoking some setter on an object, things like a SQL join or more complex queries simply have no reasonable equivalent in the object-oriented world. In addition to that, in the SQL world you have transactions, constraints and other mechanisms which are quite useful to guarantee the consistency of your data, but which can make the ORM code complicate.
The other approach instead consists in writing your own SQL code. The advantages of doing that is that you can easily access the nature of the database and let it do all the work. The disadvantage is that you end up writing a lot of SQL queries.
So which approach you should be using? I think it depends:
- do you want to support all kinds of databases? An ORM can help you with that.
- how easy is to get started? I think that an ORM tends to make things simpler at the beginning because you do not need to write much code
- maintainability over time as you find the need to do something particular (like a join) you start having to invest a lot of time to understand the internals of your ORM. Eventually you should factor out the effort needed to learn your ORM properly
- using an ORM could give you performance problems because the ORM tries to be smart about what to cache and when to persist the changes, you could get a few surprises.
In the end if I am sure that supporting one database (let’s say PostgreSQL) is enough my default choice is the lightweight approach. I have used myBatis years ago and I wanted to try Sql2o now.
Designing the Model
Let’s assume you have access to a database. During development I would suggest to use a PostgreSQL server running in a Docker container:
- if you are already using Docker do not miss the tutorial on running Spark inside a Docker container
- if you are new to Docker you could check out a tutorial I wrote about getting started with Docker from a developer point of view .
Docker or non Docker, I would assume you can now connect to your database.
Now let’s start to setup the dependencies in Maven: In addition to the Spark dependencies, you should add Sql2o and the jdbc extension specific to the database you are going to connect to. In my case I chose PostgreSQL:
<dependency>
<groupId>org.sql2o</groupId>
<artifactId>sql2o</artifactId>
<version>1.5.4</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>9.4-1201-jdbc41</version>
</dependency>
This is the schema we are going to use:
CREATE USER blog_owner WITH PASSWORD 'sparkforthewin';
CREATE DATABASE blog;
\connect blog
GRANT ALL PRIVILEGES ON DATABASE blog TO blog_owner;
CREATE TABLE posts (
post_uuid uuid primary key,
title text not null,
content text,
publishing_date date
);
CREATE TABLE comments (
comment_uuid uuid primary key,
post_uuid uuid references posts(post_uuid),
author text,
content text,
approved bool,
submission_date date
);
CREATE TABLE posts_categories (
post_uuid uuid references posts(post_uuid),
category text
);
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA public TO blog_owner;
Our data model is based on our posts. A post is identified by a unique UUID, basically a large number. Each post can be part of many categories (or possibly zero). To each post we can add comments. Comments can be approved or not. Does it all make sense so far?
Now, let’s start by defining a Model interface and one interface for each table of the database, with no references to the library we are going to use (Sql2o). The rest of your code will depend on this interface, not on the concrete implementation based on Sql2o that we are going to build. This will permit us to have testable code. For example we could use in our tests a dummy implementation storing data in memory.
public interface Model {
UUID createPost(String title, String content, List categories);
UUID createComment(UUID post, String author, String content);
List getAllPosts();
List getAllCommentsOn(UUID post);
boolean existPost(UUID post);
}
@Data
public class Post {
private UUID post_uuid;
private String title;
private String content;
private Date publishing_date;
private List categories;
}
@Data
public class Comment {
UUID comment_uuid;
UUID post_uuid;
String author;
String content;
boolean approved;
Date submission_date;
}
Implement the Model using Sql2o
Great! It is now time to write some code that could actually integrate with a real database. The code it is pretty straightforward, if you know your SQL:
public class Sql2oModel implements Model {
private Sql2o sql2o;
private UuidGenerator uuidGenerator;
public Sql2oModel(Sql2o sql2o) {
this.sql2o = sql2o;
uuidGenerator = new RandomUuidGenerator();
}
@Override
public UUID createPost(String title, String content, List<String> categories) {
try (Connection conn = sql2o.beginTransaction()) {
UUID postUuid = uuidGenerator.generate();
conn.createQuery("insert into posts(post_uuid, title, content, publishing_date) VALUES (:post_uuid, :title, :content, :date)")
.addParameter("post_uuid", postUuid)
.addParameter("title", title)
.addParameter("content", content)
.addParameter("date", new Date())
.executeUpdate();
categories.forEach((category) ->
conn.createQuery("insert into posts_categories(post_uuid, category) VALUES (:post_uuid, :category)")
.addParameter("post_uuid", postUuid)
.addParameter("category", category)
.executeUpdate());
conn.commit();
return postUuid;
}
}
@Override
public UUID createComment(UUID post, String author, String content) {
try (Connection conn = sql2o.open()) {
UUID commentUuid = uuidGenerator.generate();
conn.createQuery("insert into comments(comment_uuid, post_uuid, author, content, approved, submission_date) VALUES (:comment_uuid, :post_uuid, :author, :content, :approved, :date)")
.addParameter("comment_uuid", commentUuid)
.addParameter("post_uuid", post)
.addParameter("author", author)
.addParameter("content", content)
.addParameter("approved", false)
.addParameter("date", new Date())
.executeUpdate();
return commentUuid;
}
}
@Override
public List<Post> getAllPosts() {
try (Connection conn = sql2o.open()) {
List<Post> posts = conn.createQuery("select * from posts")
.executeAndFetch(Post.class);
posts.forEach((post) -> post.setCategories(getCategoriesFor(conn, post.getPost_uuid())));
return posts;
}
}
private List<String> getCategoriesFor(Connection conn, UUID post_uuid) {
return conn.createQuery("select category from posts_categories where post_uuid=:post_uuid")
.addParameter("post_uuid", post_uuid)
.executeAndFetch(String.class);
}
@Override
public List<Comment> getAllCommentsOn(UUID post) {
try (Connection conn = sql2o.open()) {
return conn.createQuery("select * from comments where post_uuid=:post_uuid")
.addParameter("post_uuid", post)
.executeAndFetch(Comment.class);
}
}
@Override
public boolean existPost(UUID post) {
try (Connection conn = sql2o.open()) {
List<Post> posts = conn.createQuery("select * from posts where post_uuid=:post")
.addParameter("post", post)
.executeAndFetch(Post.class);
return posts.size() > 0;
}
}
}
A few comments:
- when we want to execute several operations atomically (i.e., so if one fails no changes are persisted) we use a transaction, otherwise we just open a connection. We use the try-resource mechanism introduced in Java 8, so whatever happens transactions and connections are closed for us. Laziness wins :)
- our queries a micro-templates where values preceded by a colon are replaced by the values specified using addParameter
- when we do a select we can use executeAndFetch and Sql2o will auto-magically map the result, creating a list of objects of the given type and setting the fields corresponding to the names of the columns. Cool, eh? We can also map to simple types like a Strins when we have just one column
- when we create a post we generate a random UUID. It is very, very unlikely to generate the same UUID twice (“In other words, only after generating 1 billion UUIDs every second for the next 100 years, the probability of creating just one duplicate would be about 50%”)
This is probably all you need to know about Sql2o to write pretty complex services. Maybe you just need to refresh your SQL (do you remember how to a delete? Joins?)
Controllers
At this point we just need to use our model. Let’s see how to write the main method of our application:
public static void main( String[] args) {
CommandLineOptions options = new CommandLineOptions();
new JCommander(options, args);
logger.finest("Options.debug = " + options.debug);
logger.finest("Options.database = " + options.database);
logger.finest("Options.dbHost = " + options.dbHost);
logger.finest("Options.dbUsername = " + options.dbUsername);
logger.finest("Options.dbPort = " + options.dbPort);
logger.finest("Options.servicePort = " + options.servicePort);
port(options.servicePort);
Sql2o sql2o = new Sql2o("jdbc:postgresql://" + options.dbHost + ":" + options.dbPort + "/" + options.database,
options.dbUsername, options.dbPassword, new PostgresQuirks() {
{
// make sure we use default UUID converter.
converters.put(UUID.class, new UUIDConverter());
}
});
Model model = new Sql2oModel(sql2o);
// insert a post (using HTTP post method)
post("/posts", (request, response) -> {
ObjectMapper mapper = new ObjectMapper();
NewPostPayload creation = mapper.readValue(request.body(), NewPostPayload.class);
if (!creation.isValid()) {
response.status(HTTP_BAD_REQUEST);
return "";
}
UUID id = model.createPost(creation.getTitle(), creation.getContent(), creation.getCategories());
response.status(200);
response.type("application/json");
return id;
});
// get all post (using HTTP get method)
get("/posts", (request, response) -> {
response.status(200);
response.type("application/json");
return dataToJson(model.getAllPosts());
});
post("/posts/:uuid/comments", (request, response) -> {
ObjectMapper mapper = new ObjectMapper();
NewCommentPayload creation = mapper.readValue(request.body(), NewCommentPayload.class);
if (!creation.isValid()) {
response.status(HTTP_BAD_REQUEST);
return "";
}
UUID post = UUID.fromString(request.params(":uuid"));
if (!model.existPost(post)){
response.status(400);
return "";
}
UUID id = model.createComment(post, creation.getAuthor(), creation.getContent());
response.status(200);
response.type("application/json");
return id;
});
get("/posts/:uuid/comments", (request, response) -> {
UUID post = UUID.fromString(request.params(":uuid"));
if (!model.existPost(post)) {
response.status(400);
return "";
}
response.status(200);
response.type("application/json");
return dataToJson(model.getAllCommentsOn(post));
});
}
A few comments:
- We start by parsing our arguments. The class CommandLineOptions is not shown (but it is present on the GitHub repository). Basically JCommander takes our command line parameters and map them to field of CommandLineOptions. In this way we can specify the address or the port of the database when launching the application.
- We configure Sql2o and instantiate our Model. Pretty straightforward.
- As we saw in our first tutorial we use Jackson to parse the body of our requests into Java beans. Each of them has a method called isValid. We use it to see if the request is acceptable.
- Once we have an object representing the data associated to the request, we basically pass the content to some call of the model.
- Possibly we return the result of some call to model. We convert the Java beans to JSONstrings using dataToJson (again, look it up on GitHub for the code).
A complete example
We start the application by running:
mvn exec:java -Dexec.args="--db-host myDBServer --db-port 5432"
You will need to adapt the parameters to point to your database server. If everything works fine you should be able to invoke your service. To try your service I suggest to use the Chrome plugin Postman.
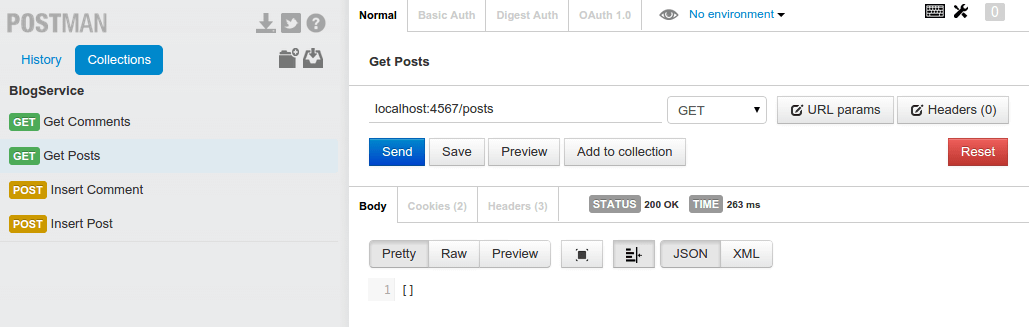
A first get to localhost:4567/posts should return an empty list of posts
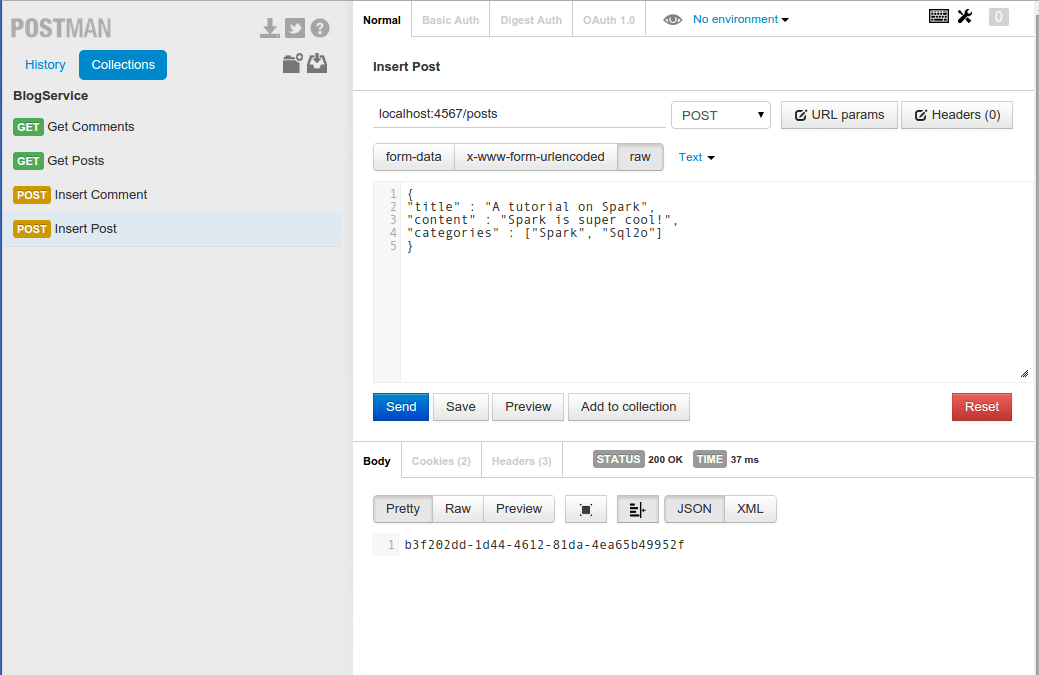
Now we insert a post with a post to localhost:4567/posts specifying the values of the post in the body of the request. We should get back the UUID of the post created.
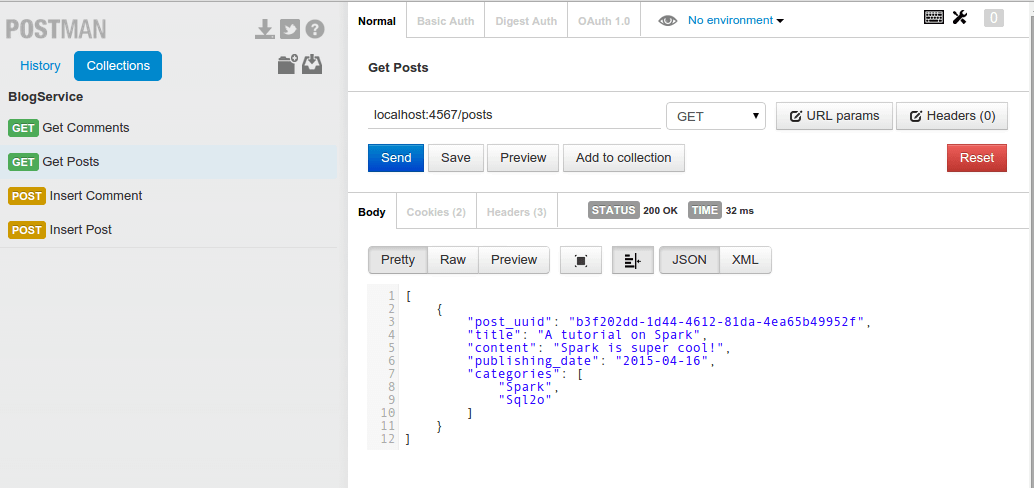
Now asking again for the list of posts we should be able to get a list of one element: the post we just inserted
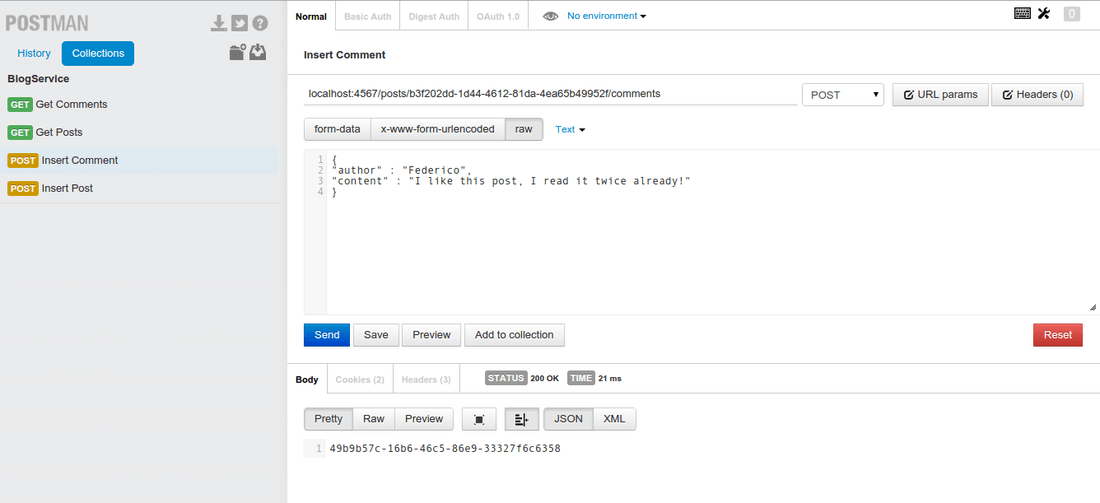
Let’s add a comment by sending a post to localhost:4567/posts/b3f202dd-1d44-4612-81da-4ea65b49952f/comments. You should change to the UUID of the post that you want to comment. Note that if you use an UUID of a not existing post you should get a 404 code back (meaning “not found”).
In this case we get back the UUID of the comment created.
Finally we should be able to get the list of comments for our post by using a get to localhost:4567/posts//b3f202dd-1d44-4612-81da-4ea65b49952f/comments
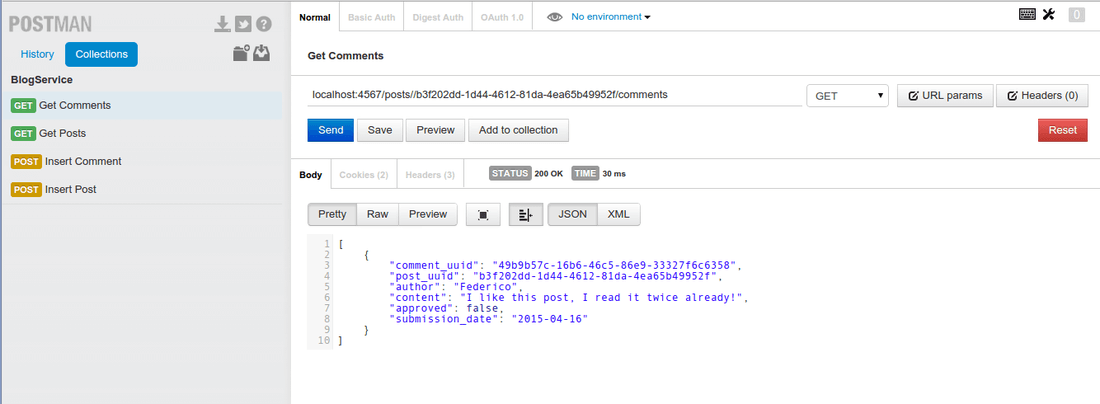
Conclusion
Our service is not complete: for example, we need endpoints to approve the comments (I am sure you can think of many other improvements). However, even if very limited, we have seen how it is possible to build a RESTful service, with persistent data in a few clear lines of Java. No long configuration files, no auto-magic components that break all of a sudden (typically on a Friday evening).
Just a few simple, reliable, understandable lines of code.
There are things we are missing: We do not properly catch exceptions which are thrown when the requests are invalid. We should definitely do that. You are a smart developer, you know what I mean and you will fix these things before deploying.
At this point we just need proper tests: We should have unit tests to verify that the controllers behave properly. To write them we could mock our Model. Testing the SQL code is more complex: I normally use functional tests. Cucumber is a nice tool and we could launch a docker container from inside our functional tests. I think that testing is the next big thing we need to focus on and probably you could soon read a specific tutorial on this website.