
News
Follow us on Twitter to get the latest news, and other Spark related content.
Spark 2.7.1 released (November 2017)
2.7.0 accidentally introduced a dependency on Jetty for one of the core classes. This dependency was removed in 2.7.1
Spark 2.7.0 released (November 2017)
A small release this time, probably the last before 3.0.0 Spark 2.7.0 is available for download on Maven Central.
See the commit history on GitHub for details.
Spark-kotlin 1.0.0-alpha released (May 2017)
At last, we’ve taken the step to kotlin and it is awesome. Spark-kotlin 1.0.0-alpha is available for download on Maven Central.
http.get("/java") {
status(404)
"Oops, are you looking for Java? You've entered the sublime domain of Kotlin"
}
Spark 2.6.0 released (April 2017)
There are some big changes this time! Spark 2.6.0 is available for download on Maven Central.
Changes
- Embedded Jetty is now fully configurable (!)
- Added
path()method for grouping routes - Added
afterAfter()filter (a finally-filter that runs after everything else) - Added
initExceptionHandler()for overriding default behavior if Sparks fails to start - Added error page handlers
internalServerError(),notFound()andadd()(general) - Added
queryParamsOrDefault()method toRequest - Added typeinfo to exceptions in
ExceptionMappers - A lot of improvements and fixes to static file handling
- MIME-type guessing
- Custom headers
- Various bugfixes
ExceptionMappers are now cleared onstop()- Fixed
OutOfMemoryErrordue to caching of chunked data - Domain has been added to
cookie(), and a bug where cookies couldn’t be deleted was fixed - Added
activeThreadCount()to expose number of active threads - Added
port()method to get current port - Add general error logging
- Added
X-Forwarded-Forsupport inrequest.ip() Spark.halt()now returnsHaltExceptioninstead ofvoid- Added
QueryParamsMap.hasKey() - Param/splat decoding now happens after matching
- Support for multiple Spark applications in filter configuration
- A lot of other minor fixes/features have also been added. See the commit history on GitHub for details.
Spark 2.5.1/2.5.2 static files vulnerability
Early November 2016 a vulnerability in how Spark 2.5/2.5.1 handles static files was exposed through a mailing list. We fixed it the same day we became aware of it, and a new version of Spark (2.5.2) was released.
The person who found the vulnerability says they tried to contact us for weeks and that we were unresponsive, but we would like to note that this attempted contact was limited to sending each of us an email using an obscure custom domain that the sender knew might get caught in gmail’s spam filter (they stated this in the email). Be assured that we do read emails and that this is the first email gmail has mistaken for spam in years.
Best practice for reporting vulnerabilities:
- Try to email us (preferably using a normal domain). Our emails are on the contact page.
- If 1 fails, create an issue on GitHub saying you need to talk to us about a vulnerability.
- If both 1 and 2 fails, create an issue on GitHub describing the vulnerability.
- If 1, 2 an 3 fails, feel free to expose the vulnerability in order to inform people. It’s not that we want to keep vulnerabilities a secret, but we want to users to have a fixed version of Spark to switch to once the vulnerability is exposed.
Spark 2.5 released (May 2016)
At last, Spark 2.5 is available for download on Maven Central. We made so many changes that we decided to skip version 2.4! … … … Okay, we did release 2.4, but there was a bug in the static file API. Since you can’t amend or remove a release on maven we had to do a new release.
New static file API:
staticFiles.location("/public");
staticFiles.externalLocation(System.getProperty("java.io.tmpdir"));
staticFiles.header("Server", "Robustified Backend");
staticFiles.expireTime(600);
Convenience API for redirects:
redirect.get("/hi", "/hello");
redirect.post("/hi", "/hello");
redirect.put("/hi", "/hello");
redirect.delete("/hi", "/hello");
redirect.any("/hi", "/hello");
Instance API
The instance API is intended for advanced users, so the official documentation will still use the static api. Everything normally available in the static API is now available on objects you can instantiate:
// When using the instance API, the Service variable should
// be called 'http' for the semantic to make sense
// ie: http.get("..."), http.post("..."), etc
public static void main(String[] args) {
igniteFirstSpark();
igniteSecondSpark();
}
static void igniteSecondSpark() {
Service http = ignite();
http.get("/basicHello", (q, a) -> "Hello from port 4567!");
}
static void igniteFirstSpark() {
Service http = ignite()
.port(8080)
.threadPool(20);
http.get("/configuredHello", (q, a) -> "Hello from port 8080!");
}
Route Overview
We’ve added an experimental feature which displays all the mapped routes of your application:
You can enable it like this:
RouteOverview.enableRouteOverview(); // overview available at /debug/routeoverview/
RouteOverview.enableRouteOverview("/my/overview/path"); // available at specified path
Spark Debug Tools
We’ve started a new project, called Spark Debug Tools (repo here)
There has also been other bugfixes and minor changes. See the commit history on GitHub for details.
Spark 2.3 released (Sep 2015)
Woop woop, Spark 2.3 is available for download on Maven Central.
Changes
- WebSocket support
- Thymeleaf template engine support
- Jetbrick template engine support
- Major improvements to implementation
- Newer versions of all dependencies
- Other minor features have also been added, as well as some bugfixes. See the commit history on GitHub for details.
Spark 2.2 released (May 2015)
Spark 2.2 is available for download on Maven Central.
New features
- GZIP support
- Support for multiple new template engines:
- Handlbars
- Pebble
- Water
- Spark jar now seen as bundle by any OSGI container
- Embedded Jetty threadpool configuration
- awaitInitialization method on SparkBase
- Unicode support for routes and params
- Methods for removing all routes (or particular ones)
- There have also been other minor bugfixes and improvements, See the commit history on GitHub for details.
Spark survey results (Apr 2015)
About the survey
For the past couple of weeks we’ve been showing users on the documentation page a survey popup (in the lower right corner though, we’re not evil). A couple of hundred users have responded to the survey now, so we’ve stopped it. We’re sorry if this annoyed anyone, but hey, at least we’re sharing the results with you.
Survey results
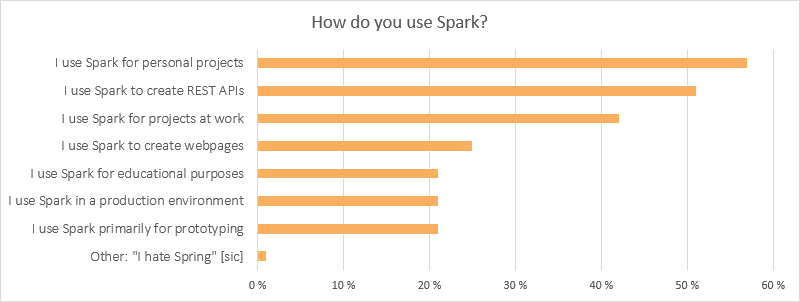
As expected, a lot of our users (51%) use Spark to create REST APIs, but the amount of people who use Spark to create webpages is pretty high too (25%). Most people use Spark for personal projects (57%), but a lot also use it at work (42%).
A surprisingly high number of our users seem to be using Spark for educational purposes, which is cool. We’ve seen the most educational traffic from Brown University (thank you Miyazaki-sensei, if you have any feedback from you or your students, please let us know).
Note: It was possible to select as many alternatives as you wanted for this question, so keep in mind that there is a lot of overlap between the different groups.
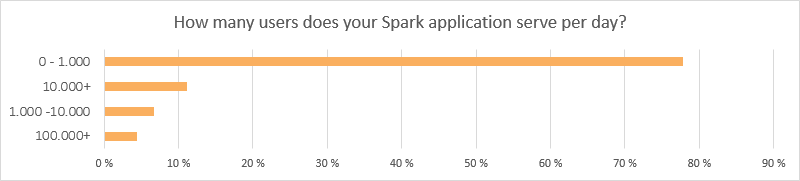
As can be seen from the first question, about 80% of our users have not deployed their application. These people have been omitted from this chart, making the sample size approximately 50 people. Still, it indicates that Spark is a viable candidate for bigger projects.
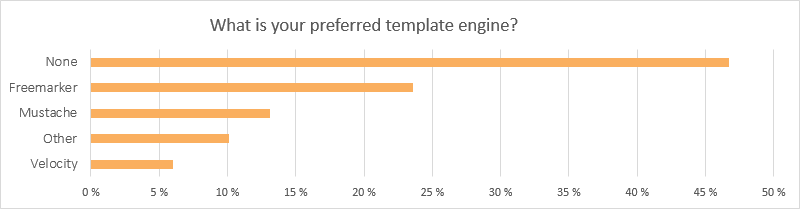
No big surprises here. As most Spark users create REST APIs without any view, they have little interest in template engines. Good news for Freemarker users though, we will work on better code examples for you guys in the coming months, showing that it’s definitely possible (and easy) to create a web application with a MVC’ish structure in Spark!
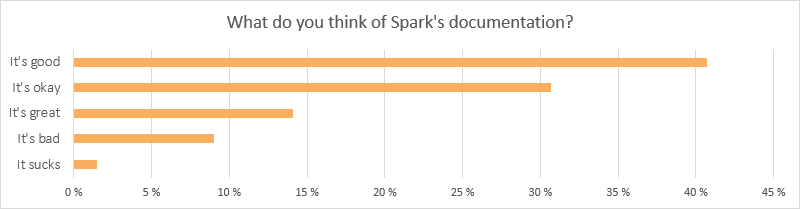
We’re glad to see that 90% of our users think that Spark’s documentation is okay or better (“Good” being the largest group at 41%). If you find any faults or have any input regarding the documentation, please let us know. We would like all our users to think that our documentation is at least okay.
Spark 2.1 released (Dec 2014)
Per has been really busy at work lately, but Spark 2.1 is available for download on Maven Central. The new version is 2.1, not 2.1.0. Since we’re aiming to be a lightweight/micro web framework, we decided that having 3 digits was too much! Also, eight more versions will probably be more than we need before the next major release of Spark (3.0).
Changes
- Added Request.bodyAsBytes() (get the body as bytes without having to convert it to String) body() is now available even if “consumed” by previous filter/route (this also solves some query map related problems)
- Allow overriding of HTTP method using X-HTTP-Method-Override header
- Static resources functionality for other application servers (previously only available for the embedded Jetty)
- Fixed MimeParse Exception
- Moved route error info to log (from 404 page)
- Replaced all System.out/System.err with slf4j logging
- Other smaller bugfixes
Spark 2.0.0 released (May 2014)
Spark 2.0.0 is available for download on Maven Central. Spark 2.0.0 is a complete rewrite of the old Spark core to provide support for the new Java 8 lambdas. The new paradigm is hugely based on the lambda philosophy, so Java 7 is officially not supported anymore. If you want to work with Java 7, you can still use Spark 1, but unfortunately it won’t be updated any longer. Please consider migrating to Java 8 if possible :)
Spark 2 Hello World
import static spark.Spark.*;
public class HelloWorld {
public static void main(String[] args) {
get("/hello", (req, res) -> "Hello World");
}
}